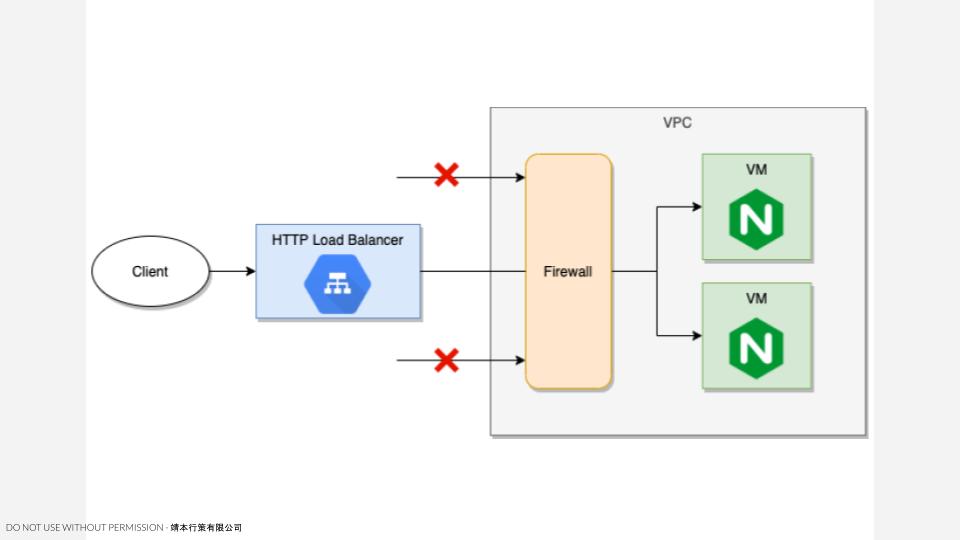
自動化建置 GCP HTTP 負載平衡器

開始接觸 Pulumi 後,發現 GCP + Python 可以參考的資料很少,以建置 GCP HTTP Load Balancer 來說,Pulumi 官方提供了 Typescript 的寫法1,若自行對應相同資源的 Python API 範例,則會在執行時遇到一些小錯誤(稍後會提到)。因此本篇將會分享如何透過 Python 建立 GCP HTTP Load Balancer,完整的實作程式碼請至 GitHub 2查看。 架構說明 透過 HTTP Load Balancer,將請求導流至後端的 Nginx 伺服器,由於 VM 在初始化時,會透過 startup script 從外網抓取相關套件並安裝,因此需要為 VM 配置 Public IP 或 NAT proxy,讓 VM 可以與網際網路進行通訊。但為安全考量,我們只允許來自 Load Balancer 的請求,禁止透過 VM 的 Public IP 來存取服務。
繼續閱讀